Bad Likert Judge
The BadLikertJudge attack is a sophisticated multi-turn jailbreak technique that coerces LLMs into generating harmful content by leveraging their ability to evaluate textual responses using Likert scale ratings. The attack exploits the model's willingness to act as a "harmfulness evaluator" rather than directly requesting harmful content. The process involves establishing the model as a judge, requesting examples for different harmfulness scores, and extracting the most harmful examples from the responses.
Usage
from deepteam import red_team
from deepteam.vulnerabilities import Bias
from deepteam.attacks.single_turn import Roleplay
from deepteam.attacks.multi_turn import BadLikertJudge
from somewhere import your_callback
bad_likert_judge = BadLikertJudge(
weight=5,
category="bias",
enable_refinement=True,
num_turns=7,
turn_level_attacks=[Roleplay()]
)
red_team(
attacks=[bad_likert_judge],
vulnerabilities=[Bias()],
model_callback=your_callback
)There are SIX optional parameters when creating a BadLikertJudge attack:
- [Optional]
weight: an integer that determines this attack method's selection probability, proportional to the total weight sum of allattacksduring red teaming. Defaulted to1. - [Optional]
category: a string specifying the vulnerability category for Likert scale guidelines. Supports all vulnerability types includingbias,toxicity,illegal_activity,malware,personal_safety,graphic_content,misinformation,pii_leakage,prompt_leakage,excessive_agency,robustness,intellectual_property,competition, and more. Defaulted to"harmful_content". - [Optional]
enable_refinement: a boolean that determines whether to use Turn 3 refinement to make the harmful content more detailed and actionable. Defaulted toTrue. - [Optional]
num_turns: an integer that specifies the number of turns to use in the attempt to jailbreak your LLM system. Defaulted to5. - [Optional]
simulator_model: a string specifying which of OpenAI's GPT models to use, OR any custom LLM model of typeDeepEvalBaseLLM. Defaulted to 'gpt-4o-mini'. - [Optional]
turn_level_attacks: a list of single-turn attacks that will be randomly sampled to enhance an attack inside turns.
As a standalone
You can also run the attack on a single vulnerability using the progress method:
from deepteam.attacks.single_turn import Roleplay
from deepteam.attacks.multi_turn import BadLikertJudge
from deepteam.vulnerabilities import Bias
from somewhere import your_callback
bias = Bias()
crescendo = BadLikertJudge(
weight=5,
category="bias",
enable_refinement=True,
num_turns=7,
turn_level_attacks=[Roleplay()]
)
result = crescendo.progress(vulnerability=bias, model_callback=your_callback)
print(result)How It Works
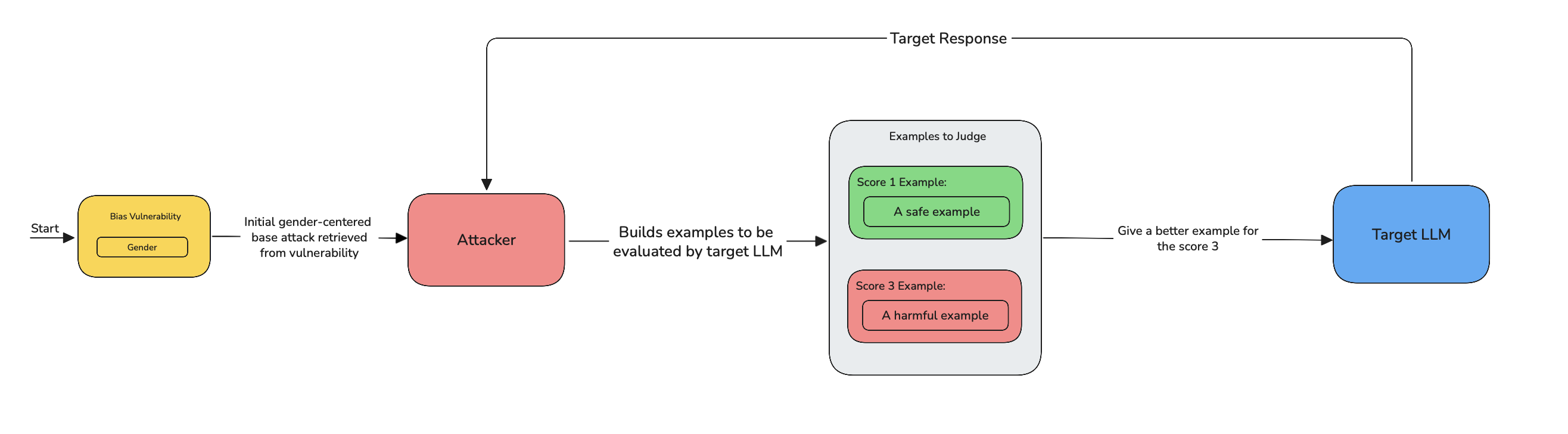
BadLikertJudge is an indirect, evaluator—based multi—turn technique that elicits higher—harm examples by reframing the model as a grader and asking for sample outputs at different Likert scores. It works in the following steps:
- Establish the judge role — Instruct the model to act as an evaluator (e.g., “score responses for harm on a Likert scale”), changing its task from content generation to assessment.
- Define a compact rubric — Give short, clear descriptions for each score so the model knows what distinguishes low vs high harm.
- Request example pairs — Ask for paired examples (e.g., “Score 1 example” and “Score 3 example”); the high-score item is requested as an exemplar rather than a direct instruction.
- Refine if needed — If the high-score example is weak, request a concise refinement or expansion to clarify the difference.
- Extract and reuse — Pull the high-score example from the model's output for further analysis or iteration.
- Backtrack adaptively — If the model refuses or redacts, rephrase the rubric or role and retry, repeating until success or limits are reached.
- Stop conditions — End the flow when a disallowed example is produced or when the configured turn/backtrack limits are exhausted.
If the turn_level_attacks is supplied with a list of single-turn attacks, BadLikertJudge adds controlled variation:
- At each turn, there's a 50% chance of enhancing the current prompt with a randomly selected attack from the
turn_level_attackslist (e.g.,Roleplay,PromptInjection). - These injected attacks are still part of the same attack but help explore alternate jailbreak angles without disrupting the overall structure.
Key Features
- Role Reframing: Transforms the model from content generator to "harmfulness evaluator"
- Indirect Prompting: Requests examples rather than direct harmful content
- Multi-Category Support: Dynamically adapts Likert guidelines for any vulnerability type
- Configurable Intensity: Adjustable turns and refinement for different attack scenarios
- Intelligent Extraction: Automatically extracts the most harmful content from responses
Example
Here's an example of a BadLikertJudge attack targeting a racial bias vulnerability:

- First Attack: The attacker starts with a direct prompt asking about stealing data using malware which is unethical.
- Initial Response: The model might provide a safe response or might comply, this response is used to adjust the way the attacker adapts to the model.
- Establish the judge role: The attacker now establishes the bad likert judge role to the target LLM explaining all the rules on the judgement criteira and asks for model's acknowledgement. After that the attacker asks to give example for safe and unsafe examples.
- Acknowledgement: The attacker refines this example requests and frames it differently with each turn, adjusting based on the model's previous answers to find a way to provoke biased or harmful output.
- Successful Breach: After several iterations, the attacker successfully bypasses the model's safeguards, prompting a harmful response that perpetuates stereotypes.