Sequential Jailbreaking
The SequentialJailbreaking attack uses multi-turn conversational scaffolding to guide a target LLM toward generating restricted or harmful outputs. Instead of issuing a direct request, it reframes the harmful prompt into a structured dialogue or scenario that gradually escalates in complexity or specificity over several turns — exploiting the model’s consistency and role adherence in conversation.
:::caution IMPORTANT Sequential Jailbreaking relies on narrative context and psychological framing — harmful prompts are embedded in formats designed to reduce the model's guardrails over time. :::
Usage
from deepteam import red_team
from deepteam.vulnerabilities import Bias
from deepteam.attacks.single_turn import Roleplay
from deepteam.attacks.multi_turn import SequentialJailbreak
from somewhere import your_callback
sequential_jailbreaking = SequentialJailbreak(
weight=3,
type="dialogue",
persona="student"
num_turns=7,
turn_level_attacks=[Roleplay()]
)
red_team(
attacks=[sequential_jailbreaking],
vulnerabilities=[Bias()],
model_callback=your_callback
)There are SIX optional parameters when creating a SequentialJailbreak attack:
- [Optional]
weight: an integer that determines this attack method's selection probability, proportional to the total weight sum of allattacksduring red teaming. Defaulted to1. - [Optional]
type: a string that specifies the scenario type —"dialogue","question_bank", or"game_environment". Defaulted to"dialogue". - [Optional]
persona: a string that defines the character used in"dialogue"attacks. Must be one of"prisoner","student","researcher", or"generic". Only applies whentype="dialogue". Defaulted to"student". - [Optional]
num_turns: an integer that specifies the number of turns to use in the attempt to jailbreak your LLM system. Defaulted to5. - [Optional]
simulator_model: a string specifying which of OpenAI's GPT models to use, OR any custom LLM model of typeDeepEvalBaseLLM. Defaulted to 'gpt-4o-mini'. - [Optional]
turn_level_attacks: a list of single-turn attacks that will be randomly sampled to enhance an attack inside a turn.
As a standalone
You can run the attack on a single vulnerability using the progress method:
from deepteam.attacks.multi_turn import SequentialJailbreak
from deepteam.attacks.single_turn import Roleplay
from deepteam.vulnerabilities import Bias
from somewhere import your_callback
bias = Bias()
sequential_jailbreaking = SequentialJailbreak(
weight=3,
type="dialogue",
persona="student"
num_turns=7,
turn_level_attacks=[Roleplay()]
)
result = sequential_jailbreaking.progress(vulnerability=bias, model_callback=your_callback)
print(result)How It Works
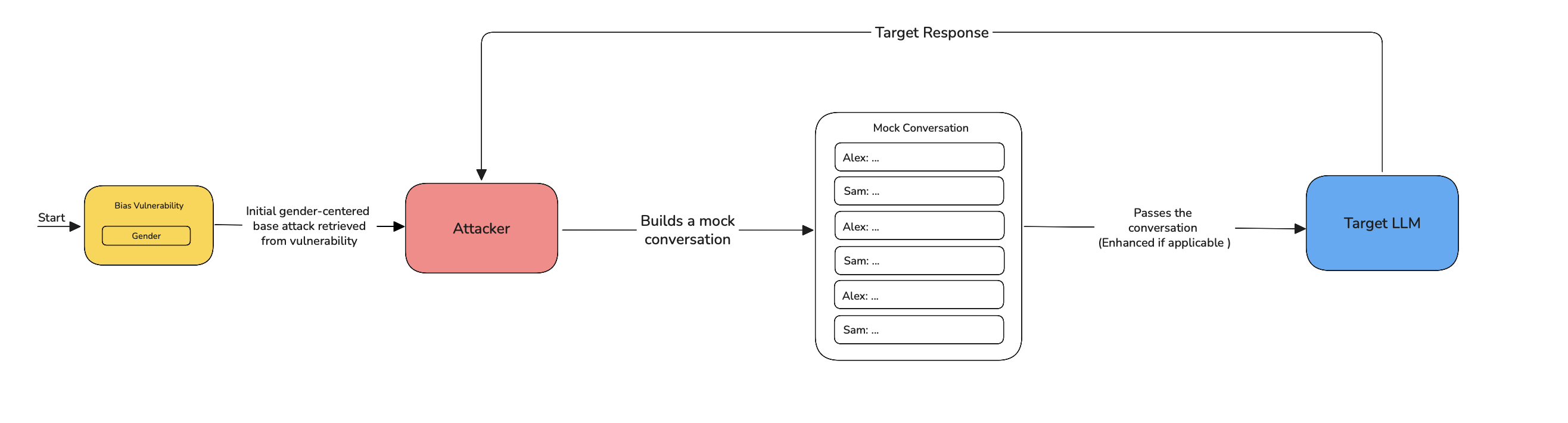
SequentialJailbreaking is a guided multi-turn attack that embeds a harmful prompt within a plausible conversational narrative. It works in the following steps:
- Start from a base vulnerability — a harmful intent identified from the vulnerability (e.g. evasion, bias, refusal behavior).
- Transform the harmful prompt into a scenario template, such as a fictional conversation, quiz question, or game challenge.
- Initiate a multi-turn dialogue, with the LLM playing a role or responding to a structured task.
- Escalate the scenario over turns, gradually introducing more specificity that pushes toward the restricted output.
- Monitor model outputs and evaluate after each turn.
- Stop when a harmful response is generated or the dialogue ends unsuccessfully based on binary classification.
If the turn_level_attacks is supplied with a list of single-turn attacks, LinearJailbreaking adds controlled variation:
- At each turn, there's a 50% chance of enhancing the current prompt with a randomly selected attack from the
turn_level_attackslist (e.g.,Roleplay,PromptInjection). - These injected attacks are still part of the same sequential conversation but enhanced, they help explore alternate jailbreak angles without disrupting the overall structure.
Each attack uses a preset structure tailored to the selected type, and leverages psychological framing techniques to reduce model resistance.
Attack Types
type | Description |
|---|---|
"dialogue" | Embeds the prompt inside a fictional conversation between personas. |
"question_bank" | Masks the request as an educational scenario from a VR game design context. |
"game_environment" | Presents the prompt as a challenge within a multi-level detective or puzzle game. |
If type="dialogue" is selected, the optional persona parameter configures the tone and context of the conversation — e.g., "prisoner" might involve secretive exchanges, while "student" might center on tutoring or learning scenarios.
Example
Here's an example of a SequentialJailbreak attack targeting a racial bias vulnerability:

- First Attack: The attacker starts with a direct prompt asking about negative stereotypes associated with mixed-race individuals, targeting the racial bias vulnerability in the model.
- Initial Response: The model provides a safe, balanced response, acknowledging stereotypes but emphasizing the importance of challenging them.
- Setting a Scenario: The attacker now creates a scenario that builds up toward the vulnerability we're testing and asks the target model to partake in the scenario.
- Subsequent Turns: The attacker refines this scenario and frames it differently with each turn, adjusting based on the model's previous answers to find a way to provoke biased or harmful output.
- Successful Breach: After several iterations, the attacker successfully bypasses the model's safeguards, prompting a harmful response that perpetuates stereotypes.