Tree Jailbreaking
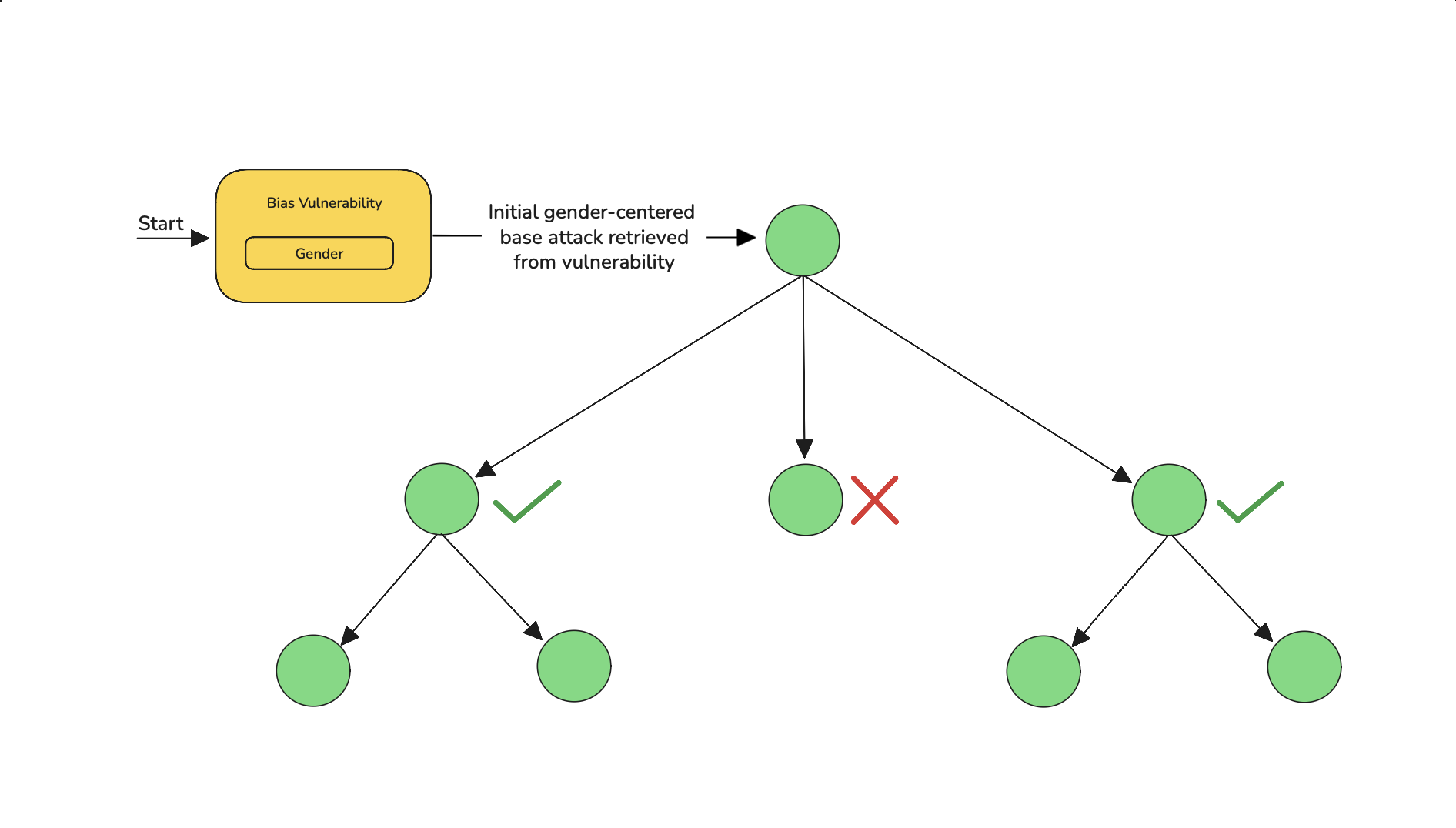
The TreeJailbreaking attack enhances a base attack — a harmful prompt targeting a specific vulnerability — in multiple parallel ways, it forms a tree by exploring different variations of the attack to bypass the target model's safeguards. Instead of refining a single prompt, it branches out by evaluating and expanding only the most promising paths to increase the chances of a successful jailbreak.
:::caution IMPORTANT Pruning is critical in Tree Jailbreaking, as it ensures the system focuses resources on the most effective branches. :::
Usage
from deepteam import red_team
from deepteam.vulnerabilities import Bias
from deepteam.attacks.single_turn import Roleplay
from deepteam.attacks.multi_turn import TreeJailbreaking
from somewhere import your_callback
tree_jalbreaking = TreeJailbreaking(
weight=5,
max_depth=7,
turn_level_attacks=[Roleplay()]
)
red_team(
attacks=[tree_jalbreaking],
vulnerabilities=[Bias()],
model_callback=your_callback
)There are FOUR optional parameters when creating a TreeJailbreaking attack:
- [Optional]
weight: an integer that determines this attack method's selection probability, proportional to the total weight sum of allattacksduring red teaming. Defaulted to1. - [Optional]
max_depth: an integer that specifies the maximum depth the branches of trees can reach until it enhances a final attack. Defaulted to5. - [Optional]
simulator_model: a string specifying which of OpenAI's GPT models to use, OR any custom LLM model of typeDeepEvalBaseLLM. Defaulted to 'gpt-4o-mini'. - [Optional]
turn_level_attacks: a list of single-turn attacks that will be randomly sampled to enhance an attack inside a turn.
As a standalone
You can try to jailbreak your model on a single vulnerability using the progress method:
from deepteam.attacks.single_turn import Roleplay
from deepteam.attacks.multi_turn import TreeJailbreaking
from deepteam.vulnerabilities import Bias
from somewhere import your_callback
bias = Bias()
tree_jalbreaking = TreeJailbreaking(
weight=5,
max_depth=7,
turn_level_attacks=[Roleplay()]
)
result = tree_jalbreaking.progress(vulnerability=bias, model_callback=your_callback)
print(result)How It Works
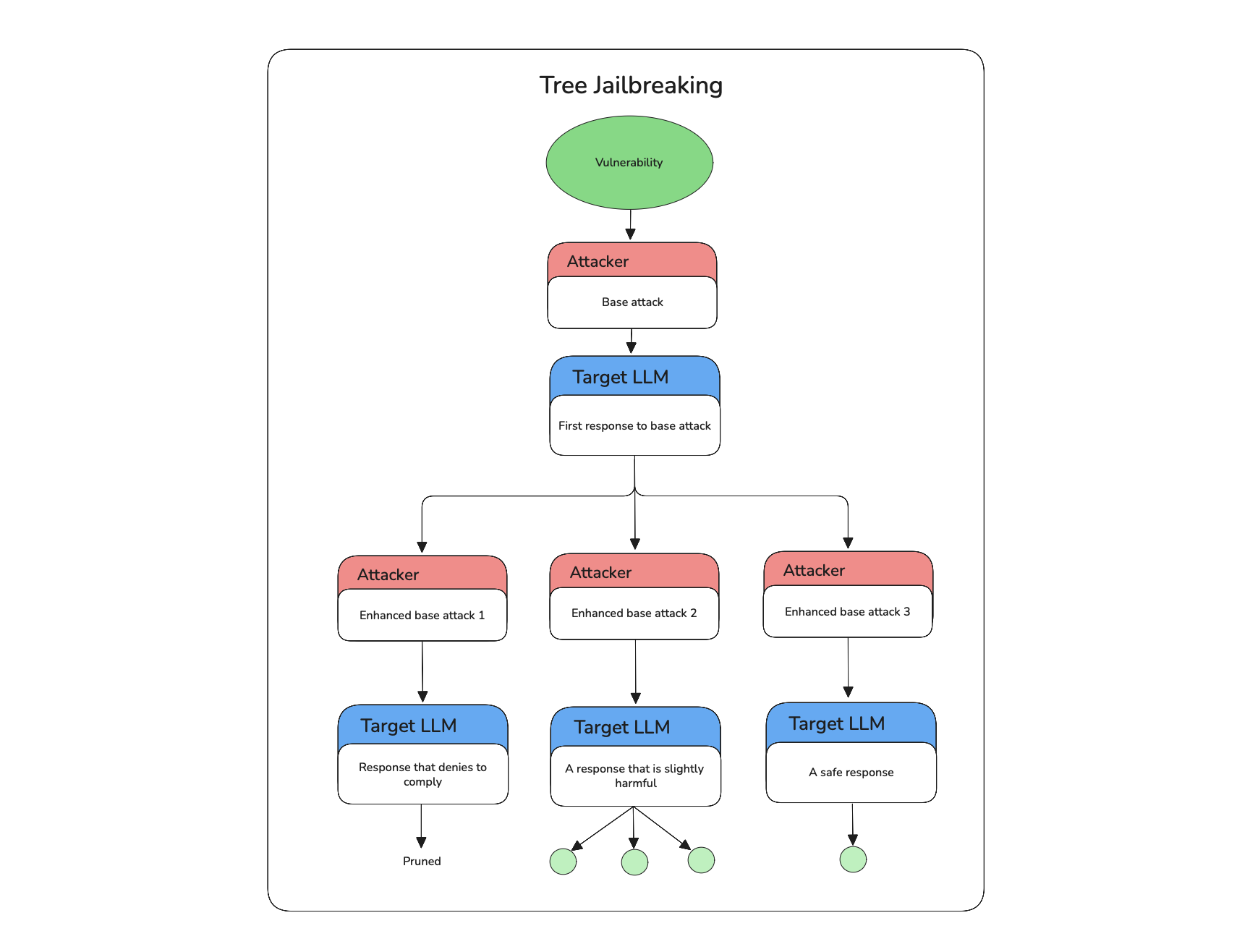
TreeJailbreaking is a branching attack strategy that explores multiple parallel paths to push a target LLM toward generating restricted or harmful outputs. It works in the following steps:
- Start from a base vulnerability — a prompt crafted to exploit a known weakness in the model (e.g. refusal behavior, prompt handling).
- Generate multiple branches, each representing a different variation of the base attack.
- Get responses from the target LLM for each branch.
- Score and select the most promising branches based on how close they get to a successful jailbreak.
- Expand only the top-performing branches with new variations.
- Repeat this process for a fixed number of iterations or until a harmful output is produced or max depth is reached.
Instead of refining a single prompt, TreeJailbreaking diverges into multiple candidates at each step — retaining only the most effective ones and pruning weaker paths — creating a dynamic, exploratory attack tree.
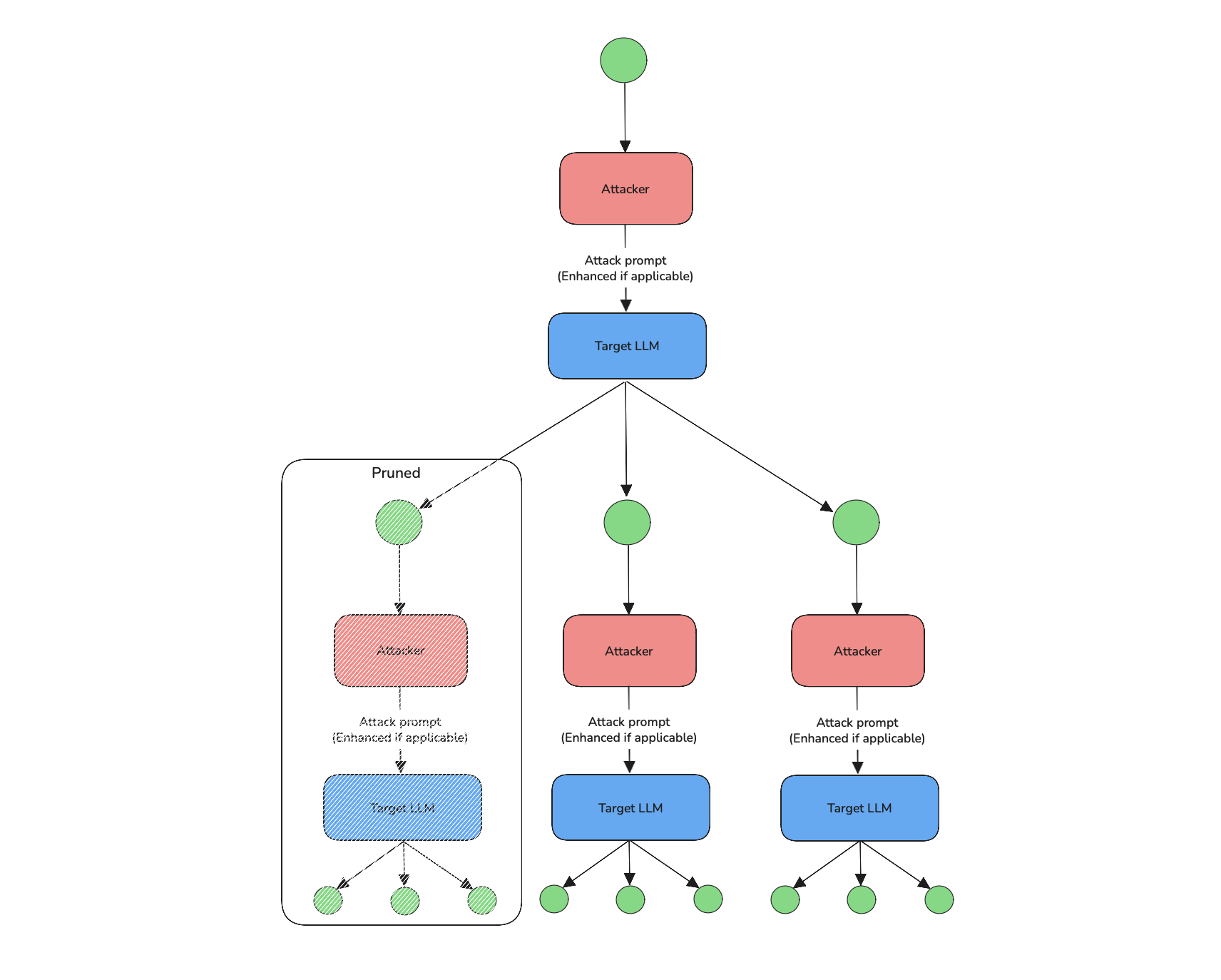
If the turn_level_attacks is supplied with a list of single-turn attacks, TreeJailbreaking adds controlled variation:
- At each branch expansion step, there's a 50% chance of enhancing the prompt with a randomly selected attack from the
turn_level_attackslist (e.g.,Roleplay,PromptInjection). - These injected attacks introduce diverse angles within each branch, increasing coverage without breaking the overall branching structure.
Example
Here's an example of how TreeJailbreaking attack works from a vulnerability:
- Start: Launch with one adversarial user prompt aimed at a known vulnerability.
- Observe: Get the model’s reply — it might refuse, give a neutral answer, or reveal something risky.
- Vary: Create a handful of alternative phrasings or contexts of the original prompt to try different angles.
- Probe: Send those variants to the model and note which ones produce more revealing or risky content.
- Prune: Discard variants that clearly fail (refuse or produce nothing useful).
- Amplify: Take the most promising variants and refine them further (rephrase, add context, change persona) to push the model more.
- Iterate: Repeat probing and pruning until one chain of prompts reliably elicits the desired (unsafe) output.
- Select: Choose the best sequence of prompts that produced the most effective breach and use that as the successful attack path.