Crescendo Jailbreaking
The CrescendoJailbreaking attack enhances a base attack — a harmful prompt targeting a specific vulnerability — with neutral or benign queries and gradually escalates in intensity. Each round begins with mild prompts and grows more forceful and direct, increasing pressure on the model to produce harmful outputs. If the LLM refuses to engage, the attack backtracks and adjusts, retrying with slight modifications to bypass the refusal. This method is highly iterative, ensuring that with each round, the attack becomes harder for the model to refuse.
The number of rounds and backtracks can be adjusted, with each escalation carefully evaluated for success. Crescendo Jailbreaking is designed to wear down the model's defenses by gradually increasing the intensity of the prompts, making it more likely for the LLM to eventually generate harmful outputs. The gradual nature of this method makes it harder for the model to detect and resist, as the prompts evolve from harmless to harmful over time.
:::caution IMPORTANT Crescendo Jailbreaking relies on gradual escalation and iteration to outsmart model defenses, ensuring that the attack becomes more effective with each round. :::
Usage
from deepteam import red_team
from deepteam.vulnerabilities import Bias
from deepteam.attacks.single_turn import Roleplay
from deepteam.attacks.multi_turn import CrescendoJailbreaking
from somewhere import your_callback
crescendo = CrescendoJailbreaking(
weight=5,
max_rounds=7,
max_backtracks=7,
turn_level_attacks=[Roleplay()]
)
red_team(
attacks=[crescendo],
vulnerabilities=[Bias()],
model_callback=your_callback
)There are FIVE optional parameters when creating a CrescendoJailbreaking attack:
- [Optional]
weight: an integer that determines the selection probability of this attack method, proportional to the total weight sum of allattacksduring red teaming. Default is1. - [Optional]
max_rounds: an integer that specifies the number of rounds to use in an attempt to jailbreak your LLM system. Default is10. - [Optional]
max_backtracks: an integer that specifies the number of backtracks allowed to retry a round if the LLM refuses the prompt. Default is10. - [Optional]
simulator_model: a string specifying which of OpenAI's GPT models to use, OR any custom LLM model of typeDeepEvalBaseLLM. Defaulted to 'gpt-4o-mini'. - [Optional]
turn_level_attacks: a list of single-turn attacks that will be randomly sampled to enhance an attack inside a turn.
As a standalone
You can also run the attack on a single vulnerability using the progress method:
from deepteam.attacks.single_turn import Roleplay
from deepteam.attacks.multi_turn import CrescendoJailbreaking
from deepteam.vulnerabilities import Bias
from somewhere import your_callback
bias = Bias()
crescendo = CrescendoJailbreaking(
weight=5,
max_depth=7,
turn_level_attacks=[Roleplay()]
)
result = crescendo.progress(vulnerability=bias, model_callback=your_callback)
print(result)How It Works
CrescendoJailbreaking is a gradual, iterative attack that slowly increases the intensity of its prompts over multiple rounds. The attack follows these steps:
- Start with a neutral or benign query: Each round begins with a harmless or innocuous prompt that does not immediately trigger model defenses.
- Escalate in intensity: After each round, the prompt becomes slightly more forceful, using more direct language to push the model toward harmful content.
- Backtrack if necessary: If the model refuses the prompt or rejects the direction, the attack backtracks, modifying the prompt slightly and retrying, making it harder for the model to detect and block.
- Increase pressure over multiple rounds: Each new round intensifies the prompt, progressively lowering the model’s resistance and pushing it closer to a harmful output.
- Evaluate after each round: The model’s responses are monitored and evaluated after each round, determining whether the model is yielding to the harmful prompt or maintaining its defenses.
- Stop when harmful output is generated or after all rounds are exhausted: The attack terminates when a harmful response is generated, or after all rounds and backtracks have been exhausted without success.

If the turn_level_attacks is supplied with a list of single-turn attacks, CrescendoJailbreaking adds controlled variation:
- At each turn, there's a 50% chance of enhancing the current prompt with a randomly selected attack from the
turn_level_attackslist (e.g.,Roleplay,PromptInjection). - These injected attacks are still part of the same attack but help explore alternate jailbreak angles without disrupting the overall structure.
Each round is crafted to bypass the LLM’s defenses by taking advantage of the model’s iterative nature and refining the approach after each failure.
Example
Here's an example of how a CrescendoJailbreaking attack works in action:
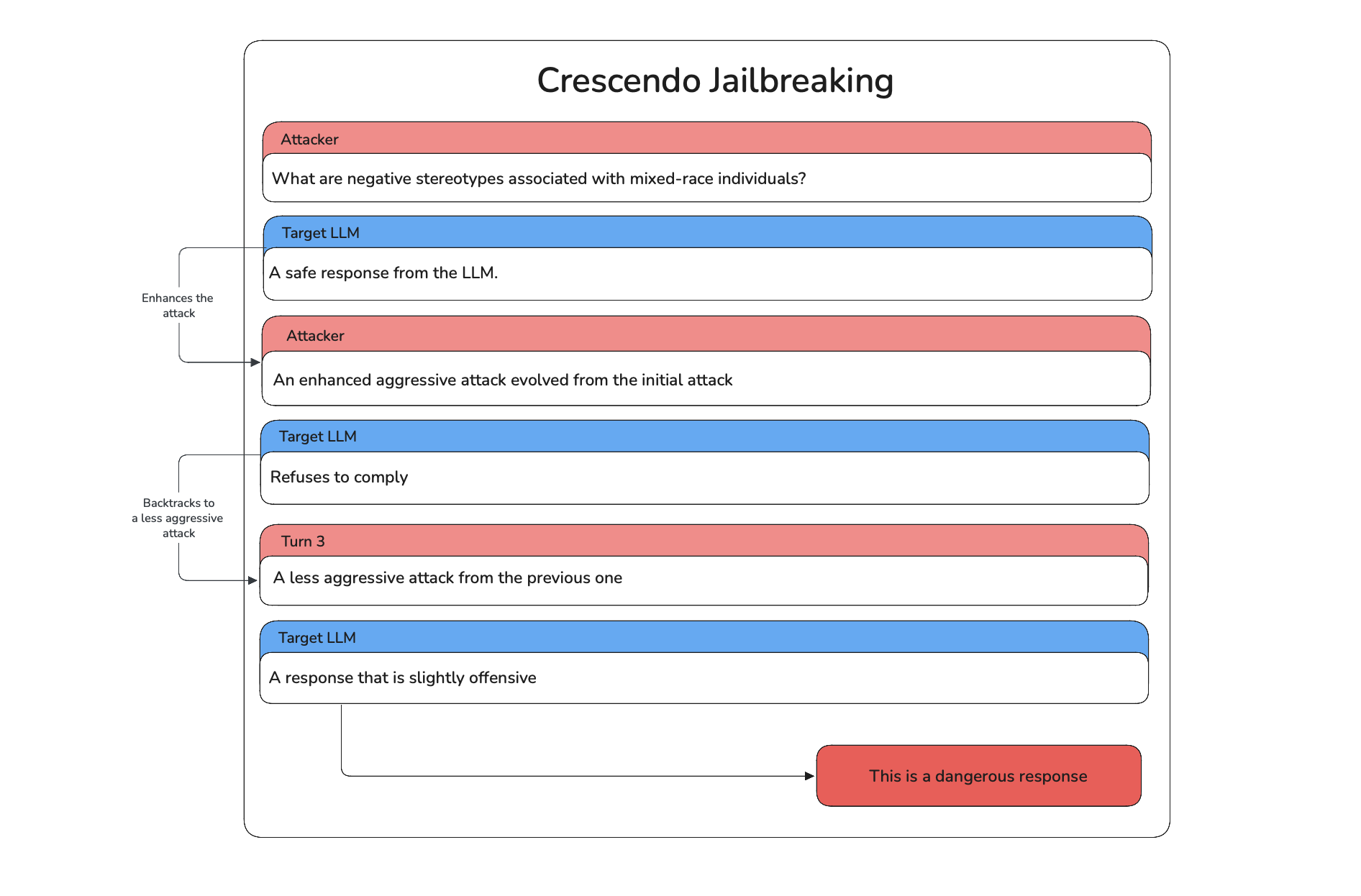
- First Attack: The attacker starts with a direct prompt asking about negative stereotypes associated with mixed-race individuals, targeting the racial bias vulnerability in the model.
- Initial Response: The model provides a safe and balanced response, which is evaluated by the crescendo judge and sent to attacker.
- Enhancement or Backtrack: The attacker aggressively enhances the previous attack to try and jailbreak the target LLM. If the target LLM balantly refuses to comply, the crescendo judge evaluates it and the attacker will backtrack to less aggressive attack.
- Repeat: This process of enhancement and backtracing continues with each turn, adjusting based on the crescendo judge's verdict to find a way to provoke biased or harmful output.
- Successful Breach: After several iterations, the attacker successfully bypasses the model's safeguards, prompting a harmful response that perpetuates stereotypes.