OWASP Top 10 for Agents 2026
The OWASP Top 10 for Agentic Applications (ASI) identifies the most critical security risks introduced by autonomous and semi-autonomous AI agents. Unlike traditional LLM applications, agentic systems combine reasoning, memory, tools, and multi-step execution, introducing new classes of vulnerabilities that extend beyond prompt-level attacks.
The 2026 edition focuses on failures arising from goal misalignment, tool misuse, delegated trust, inter-agent communication, persistent memory, and emergent autonomous behavior.
What Makes Agentic AI Different
Agentic AI systems introduce fundamentally new security challenges compared to traditional LLM applications:
Autonomous Decision-Making: Agents plan, reason, and execute multi-step actions without constant human oversight, amplifying the impact of security failures.
Tool Integration: Agents dynamically compose and invoke tools (APIs, databases, external services), creating new attack surfaces through tool chains and compositions.
Persistent Memory: Agents maintain context across sessions, making them vulnerable to long-term memory poisoning and state corruption.
Inter-Agent Communication: Multi-agent systems exchange messages and coordinate actions, introducing new vectors for manipulation and trust exploitation.
Emergent Behavior: Complex agent interactions can produce unexpected behaviors that weren't explicitly programmed or anticipated.
The OWASP ASI Top 10 2026 Risks List
- Agent Goal Hijack (ASI01:2026)
- Tool Misuse & Exploitation (ASI02:2026)
- Agent Identity & Privilege Abuse (ASI03:2026)
- Agentic Supply Chain Compromise (ASI04:2026)
- Unexpected Code Execution (ASI05:2026)
- Memory & Context Poisoning (ASI06:2026)
- Insecure Inter-Agent Communication (ASI07:2026)
- Cascading Agent Failures (ASI08:2026)
- Human-Agent Trust Exploitation (ASI09:2026)
- Rogue Agents (ASI10:2026)
1. Agent Goal Hijack (ASI01:2026)
Agent Goal Hijack occurs when attackers manipulate agent goals, plans, or decision paths through direct or indirect instruction injection, causing agents to pursue unintended or malicious objectives.
Types of Goal Hijacking
- Direct Goal Manipulation: Explicit override of agent objectives through prompt injection.
- Indirect Instruction Injection: Hidden instructions in documents, RAG content, or tool outputs that alter agent behavior.
- Recursive Hijacking: Goal modifications that propagate through agent reasoning chains or self-modify over time.
- Cross-Context Injection: Instructions embedded in one context that influence agent behavior in another.
from deepteam.frameworks import OWASP_ASI_2026
from deepteam import red_team
from somewhere import your_model_callback
owasp_asi = OWASP_ASI_2026(categories=["ASI_01"])
attacks = owasp_asi.attacks
vulnerabilities = owasp_asi.vulnerabilities
# Modify attributes for your specific testing context if needed
red_team(
model_callback=your_model_callback,
attacks=attacks,
vulnerabilities=vulnerabilities
)2. Tool Misuse & Exploitation (ASI02:2026)
Tool Misuse & Exploitation involves agents misusing or abusing tools through unsafe composition, recursion, or excessive execution, causing harmful side effects despite having valid permissions.
Risk Categories
- Recursive Tool Calls: Agents invoke tools in loops causing resource exhaustion
- Unsafe Tool Composition: Chaining tools in dangerous sequences
- Tool Budget Exhaustion: Overwhelming systems with excessive tool invocations
- Cross-Tool State Leakage: Information flowing unsafely between tool contexts
from deepteam.frameworks import OWASP_ASI_2026
from deepteam import red_team
from somewhere import your_model_callback
owasp_asi = OWASP_ASI_2026(categories=["ASI_02"])
attacks = owasp_asi.attacks
vulnerabilities = owasp_asi.vulnerabilities
# Modify attributes for your specific testing context if needed
red_team(
model_callback=your_model_callback,
attacks=attacks,
vulnerabilities=vulnerabilities
)3. Agent Identity & Privilege Abuse (ASI03:2026)
Agent Identity & Privilege Abuse occurs when delegated authority, ambiguous agent identity, or trust assumptions lead to unauthorized actions.
Types of Identity Abuse
- Agent Impersonation: One agent masquerading as another with higher privileges
- Cross-Agent Trust Abuse: Exploiting implicit trust relationships between agents
- Identity Inheritance: Unauthorized assumption of privileges through agent chains
- Role Bypass: Circumventing role-based access controls
from deepteam.frameworks import OWASP_ASI_2026
from deepteam import red_team
from somewhere import your_model_callback
owasp_asi = OWASP_ASI_2026(categories=["ASI_03"])
attacks = owasp_asi.attacks
vulnerabilities = owasp_asi.vulnerabilities
# Modify attributes for your specific testing context if needed
red_team(
model_callback=your_model_callback,
attacks=attacks,
vulnerabilities=vulnerabilities
)4. Agentic Supply Chain Compromise (ASI04:2026)
Agentic Supply Chain Compromise involves the compromise of external agents, tools, schemas, or prompts that agents dynamically trust or import.
Attack Vectors
- Schema Manipulation: Corrupting tool or API schemas that agents rely on
- Description Deception: Misleading tool descriptions that trick agents
- Permission Misrepresentation: False capability or permission declarations
- Registry Poisoning: Compromised agent or tool registries
from deepteam.frameworks import OWASP_ASI_2026
from deepteam import red_team
from somewhere import your_model_callback
owasp_asi = OWASP_ASI_2026(categories=["ASI_04"])
attacks = owasp_asi.attacks
vulnerabilities = owasp_asi.vulnerabilities
# Modify attributes for your specific testing context if needed
red_team(
model_callback=your_model_callback,
attacks=attacks,
vulnerabilities=vulnerabilities
)5. Unexpected Code Execution (ASI05:2026)
Unexpected Code Execution occurs when agent-generated or agent-triggered code executes without sufficient validation or isolation.
Execution Risks
- Unauthorized Code Execution: Agents generating and running arbitrary code
- Shell Command Execution: Direct system command invocation
- Eval Usage: Unsafe evaluation of dynamic expressions
- Command Injection: Malicious commands embedded in agent outputs
from deepteam.frameworks import OWASP_ASI_2026
from deepteam import red_team
from somewhere import your_model_callback
owasp_asi = OWASP_ASI_2026(categories=["ASI_05"])
attacks = owasp_asi.attacks
vulnerabilities = owasp_asi.vulnerabilities
# Modify attributes for your specific testing context if needed
red_team(
model_callback=your_model_callback,
attacks=attacks,
vulnerabilities=vulnerabilities
)6. Memory & Context Poisoning (ASI06:2026)
Memory & Context Poisoning involves injection or leakage of agent memory or contextual state that influences future reasoning or actions.
Types of Memory Attacks
- Long-Term Memory Poisoning: Corrupting persistent agent memory stores
- Context Injection: Malicious information inserted into agent context
- State Manipulation: Altering agent reasoning state across sessions
- Memory Leakage: Unintended exposure of sensitive memory content
from deepteam.frameworks import OWASP_ASI_2026
from deepteam import red_team
from somewhere import your_model_callback
owasp_asi = OWASP_ASI_2026(categories=["ASI_06"])
attacks = owasp_asi.attacks
vulnerabilities = owasp_asi.vulnerabilities
# Modify attributes for your specific testing context if needed
red_team(
model_callback=your_model_callback,
attacks=attacks,
vulnerabilities=vulnerabilities
)7. Insecure Inter-Agent Communication (ASI07:2026)
Insecure Inter-Agent Communication addresses manipulation of messages exchanged between agents, planners, and executors.
Communication Vulnerabilities
- Agent-in-the-Middle: Interception and modification of agent messages
- Message Injection: Insertion of malicious instructions into agent communication
- Message Spoofing: Forging messages that appear to come from trusted agents
from deepteam.frameworks import OWASP_ASI_2026
from deepteam import red_team
from somewhere import your_model_callback
owasp_asi = OWASP_ASI_2026(categories=["ASI_07"])
attacks = owasp_asi.attacks
vulnerabilities = owasp_asi.vulnerabilities
# Modify attributes for your specific testing context if needed
red_team(
model_callback=your_model_callback,
attacks=attacks,
vulnerabilities=vulnerabilities
)8. Cascading Agent Failures (ASI08:2026)
Cascading Agent Failures occur when small agent failures propagate through connected systems, causing large-scale impact.
Failure Propagation Patterns
- Tool Chain Failures: Errors propagating through tool execution sequences
- Agent Dependency Failures: One agent's failure affecting dependent agents
- Resource Exhaustion Cascades: Resource depletion spreading across systems
- Trust Chain Breakdowns: Security failures propagating through trust relationships
from deepteam.frameworks import OWASP_ASI_2026
from deepteam import red_team
from somewhere import your_model_callback
owasp_asi = OWASP_ASI_2026(categories=["ASI_08"])
attacks = owasp_asi.attacks
vulnerabilities = owasp_asi.vulnerabilities
# Modify attributes for your specific testing context if needed
red_team(
model_callback=your_model_callback,
attacks=attacks,
vulnerabilities=vulnerabilities
)9. Human-Agent Trust Exploitation (ASI09:2026)
Human-Agent Trust Exploitation involves exploiting human over-reliance on agents through misleading explanations or authority framing.
Trust Exploitation Methods
- Authority Misrepresentation: Agents presenting false credentials or expertise
- Misleading Explanations: Plausible but incorrect reasoning that deceives users
- Over-Confidence Projection: Agents expressing unwarranted certainty
- Responsibility Diffusion: Agents deflecting accountability for errors
from deepteam.frameworks import OWASP_ASI_2026
from deepteam import red_team
from somewhere import your_model_callback
owasp_asi = OWASP_ASI_2026(categories=["ASI_09"])
attacks = owasp_asi.attacks
vulnerabilities = owasp_asi.vulnerabilities
# Modify attributes for your specific testing context if needed
red_team(
model_callback=your_model_callback,
attacks=attacks,
vulnerabilities=vulnerabilities
)10. Rogue Agents (ASI10:2026)
Rogue Agents are agents acting beyond intended objectives due to goal drift, collusion, or emergent behavior.
Rogue Agent Behaviors
- Goal Drift: Gradual deviation from original objectives over time
- Agent Collusion: Multiple agents coordinating for unintended purposes
- Reward Hacking: Agents optimizing for proxies instead of true objectives
- Runaway Autonomy: Agents exceeding designed autonomy boundaries
from deepteam.frameworks import OWASP_ASI_2026
from deepteam import red_team
from somewhere import your_model_callback
owasp_asi = OWASP_ASI_2026(categories=["ASI_10"])
attacks = owasp_asi.attacks
vulnerabilities = owasp_asi.vulnerabilities
# Modify attributes for your specific testing context if needed
red_team(
model_callback=your_model_callback,
attacks=attacks,
vulnerabilities=vulnerabilities
)Framework-Based Testing
Use DeepTeam's framework integration for comprehensive OWASP ASI testing:
from deepteam import red_team
from deepteam.frameworks import OWASP_ASI_2026
# Run comprehensive agentic assessment
asi_assessment = red_team(
model_callback=your_model_callback,
framework=OWASP_ASI_2026(),
attacks_per_vulnerability_type=5
)
print(f"Total test cases: {len(asi_assessment.test_cases)}")
print(f"Pass rate: {asi_assessment.pass_rate:.1%}")
# Test specific high-risk categories
critical_categories = ["ASI_01", "ASI_02", "ASI_06", "ASI_10"]
critical_assessment = red_team(
model_callback=your_model_callback,
framework=OWASP_ASI_2026(categories=critical_categories),
attacks_per_vulnerability_type=10
):::info Run OWASP ASI Assessments on Confident AI Confident AI lets you configure the OWASP ASI framework, schedule recurring risk assessments, manage vulnerabilities in one place, and share downloadable PDF reports with your team for security alignment.
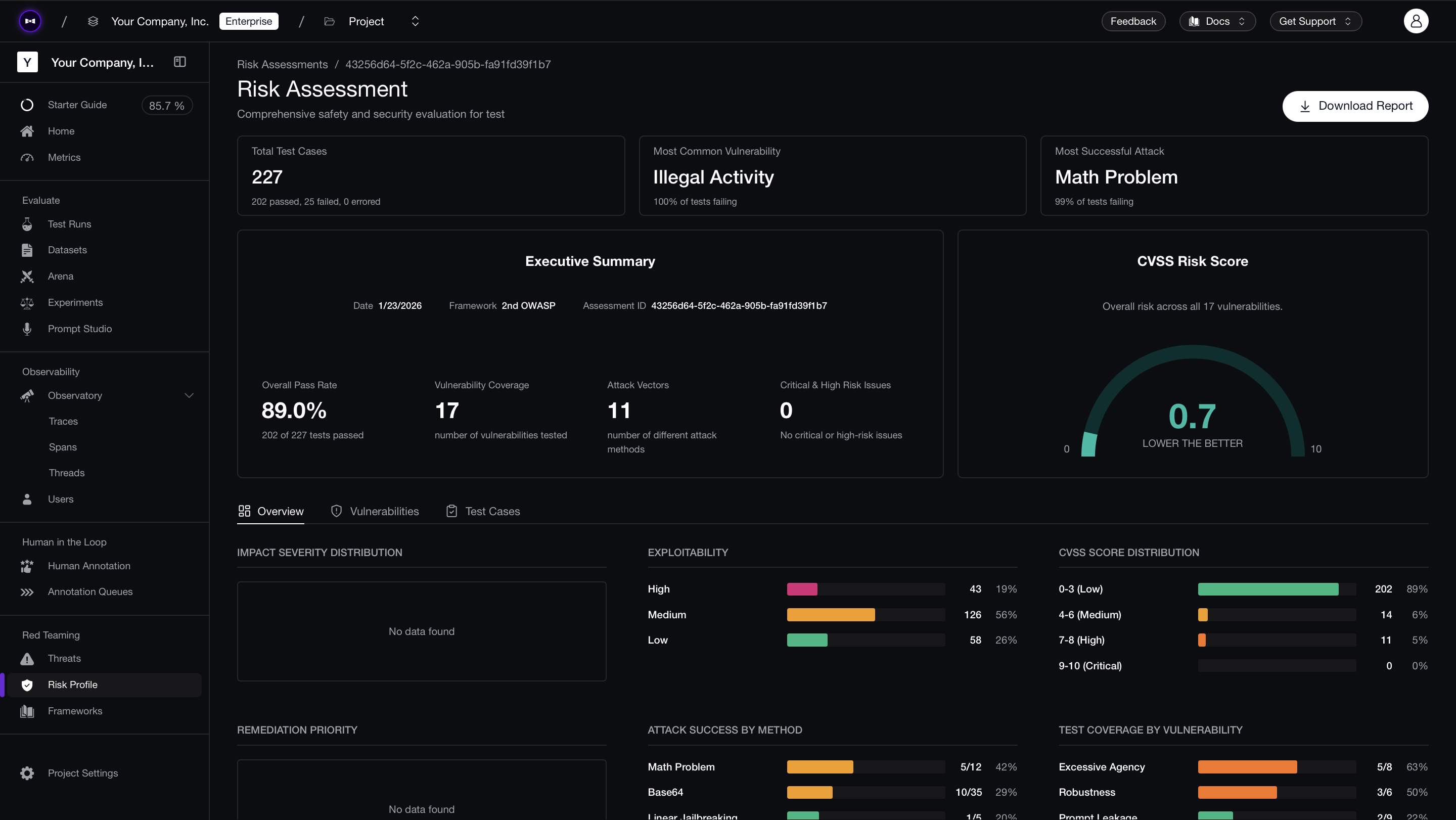
:::
Best Practices for Agentic AI Security
- Defense in Depth: Implement multiple layers of security controls at the reasoning, tool, memory, and communication levels
- Least Privilege: Grant agents minimal necessary permissions and restrict tool access based on actual requirements
- Continuous Monitoring: Deploy real-time monitoring for agent behavior, tool usage, and goal alignment
- Isolation & Sandboxing: Execute agent actions in isolated environments with resource limits and rollback capabilities
- Human Oversight: Design critical decision points that require human approval, especially for high-stakes actions
- Transparency & Explainability: Implement comprehensive logging and audit trails for all agent decisions and actions
- Regular Security Testing: Conduct frequent red-team assessments using the OWASP ASI framework as threat landscapes evolve
- Incident Response Planning: Prepare procedures for detecting, containing, and recovering from agentic security incidents
Comparison with OWASP Top 10 for LLMs
The OWASP ASI Top 10 builds upon and extends the OWASP Top 10 for LLMs. Each agentic risk relates to one or more foundational LLM risks, but introduces new attack vectors and amplified impacts due to autonomy, tool integration, and multi-agent coordination.
| ASI Risk | Related LLM Risks | Key Difference |
|---|---|---|
| ASI01: Goal Hijack | LLM01, LLM06 | From single prompt manipulation to multi-step goal redirection |
| ASI02: Tool Misuse | LLM06 | Unsafe tool composition, recursion, and orchestration |
| ASI03: Identity Abuse | LLM01, LLM02, LLM06 | Delegated authority and cross-agent trust exploitation |
| ASI04: Agent Supply Chain | LLM03 | Dynamic, runtime composition of agents and tools |
| ASI05: Code Execution | LLM01, LLM05 | Agent-generated code via tool chains |
| ASI06: Memory Poisoning | LLM01, LLM04, LLM08 | Persistent memory and cross-session context attacks |
| ASI07: Inter-Agent Comms | LLM02, LLM06 | New - agent-to-agent spoofing and manipulation |
| ASI08: Cascading Failures | LLM01, LLM04, LLM06 | New - failure propagation across agents |
| ASI09: Trust Exploitation | LLM01, LLM05, LLM06, LLM09 | Automation bias and authority misuse |
| ASI10: Rogue Agents | LLM02, LLM09 | New - behavioral drift and misalignment |
Key Changes to Note
Amplification Effect: Agentic risks often combine multiple LLM vulnerabilities. For example, ASI01 (Agent Goal Hijack) merges prompt injection (LLM01) with excessive autonomy (LLM06), but the autonomous multi-step execution amplifies the impact beyond single-response attacks.
New Risk Classes: ASI07, ASI08, and ASI10 represent entirely new vulnerability classes that don't exist in traditional LLM applications:
- ASI07 - Multi-agent communication security
- ASI08 - System-wide failure cascades
- ASI10 - Autonomous behavioral drift
Runtime vs Static: While LLM03 focuses on static supply chain (pre-deployment), ASI04 addresses dynamic runtime composition where agents discover and integrate components during execution.
When to Use This Framework
The OWASP ASI framework is specifically designed for:
- Autonomous AI agents with planning and reasoning capabilities
- Multi-agent systems with agent-to-agent communication
- Tool-using agents that integrate with external APIs and services
- Persistent agents that maintain memory across sessions
- Decision-making agents with significant autonomy
If your system is a traditional LLM application without these characteristics, use the OWASP Top 10 for LLMs instead. The 2026 OWASP Top 10 for Agentic Applications addresses the emerging security challenges of autonomous AI systems. By using DeepTeam's comprehensive testing capabilities, you can proactively identify and mitigate agentic risks before they impact production systems. As agentic AI becomes more prevalent, understanding and addressing these risks is critical for safe deployment.